
このガイドは、初心者がScreaming Frog SEO Spiderを使い始めるためのものです。初期セットアップ、クロールの開始方法、発見されたレポートや問題の表示について説明しています。
インストール
一度に500URLまでクロールできるSEO Spiderを無料でダウンロードし、インストールする必要があります。Windows、MacOS、Ubuntuで利用可能です。以下のダウンロードボタンをクリックしてください。
次に、ダウンロードしたSEO Spiderのインストールファイルをダブルクリックし、インストーラの手順に従ってください。
ライセンスを購入すると、500URLのクロール制限が解除され、設定が開放され、より高度な機能を利用することができるようになります。無料と有料の機能比較は、価格ページをご覧ください。
ライセンスの有効化
無料版をご利用になる場合は、このステップは無視していただいて結構です。ただし、500URL以上のクロール、クロールの保存と再開、高度な機能の利用を希望する場合は、ライセンスを購入することができます。
ライセンスを購入すると、ユーザー名とライセンスキーが提供されますので、アプリケーション内の「ライセンス > ライセンスキーの入力」で入力してください。
正しく入力されると、ライセンスは有効であると表示され、有効期限が表示されます。その後、アプリケーションを再起動することで、クロールの制限が解除され、設定や有料機能にアクセスできるようになります。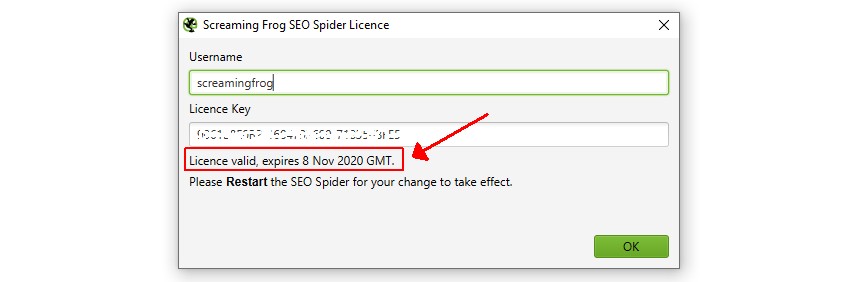 ライセンスが無効と表示された場合は、FAQの「ライセンスが無効な場合のトラブルシューティング」をお読みください。
ライセンスが無効と表示された場合は、FAQの「ライセンスが無効な場合のトラブルシューティング」をお読みください。
メモリとストレージのセットアップ
無料版をお使いの方や、すぐにクロールを始めたい方は、このステップを無視していただいて結構です。しかし、有料版をお使いの場合は、最初にこの設定をすることをお勧めします。
SSDを使用している場合、データベースストレージモードに切り替えることをお勧めします。設定 > システム > ストレージモード」で「データベースストレージモード」を選択します。
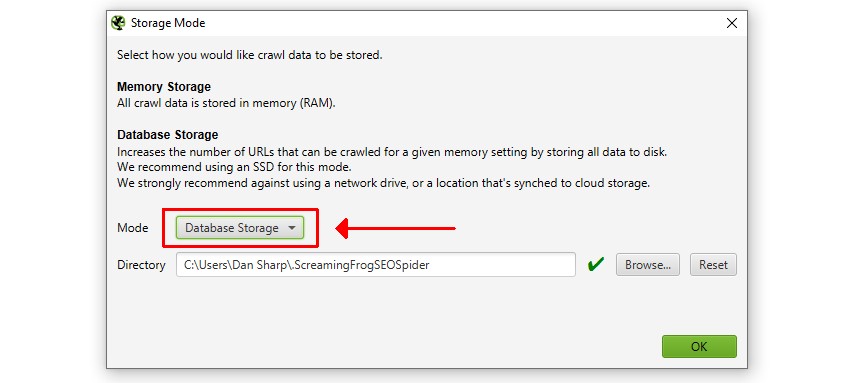
データベースストレージモードでは、SEOスパイダーがより多くのURLをクロールし、クロールデータを自動的に保存し、古いクロールに素早くアクセスできるようになるなど、大きな利点があります。
SSDをお持ちでない場合は、RAMストレージモードにしてください。RAMに余裕があれば、クロールを保存し、たくさんのURLをクロールすることができます。これでクロールを開始する準備が整いました。
クロールを開始する
クロールには、大きく分けて2つのモードがあります。ウェブサイトをクロールするデフォルトの「スパイダー」モードと、クロールするURLのリストをアップロードできる「リスト」モードです。
スパイダーモードでは、「Enter URL to spider」フィールドにホームページを入力して「Start」をクリックすると、通常のクロールを開始することができます。

入力されたURLと、同じサブドメイン内のページのHTMLにあるハイパーリンクから発見できるすべてのURLをクロールし、監査します。
クロールはリアルタイムに更新され、その速度や完了したURLの総数、残りのURLの総数がアプリケーションの下部で表示されます。
クロールは「一時停止」をクリックすれば、いつでも「再開」することができます。また、クロールを保存しておいて、後で再開することも可能です。
サイト全体ではなく、URLのリストをクロールしたい場合は、「モード > リスト」をクリックしてURLのリストをアップロードまたは貼り付けることができます。

クロールの設定
SEO Spiderは、Googleと同様の方法でクロールするように初期設定されているため、クロールするための設定を調整する必要はありません。
しかし、あなたが望むデータを取得するためにクロールを設定する方法は無数にあります。各設定の詳細については、ユーザーガイドを参照してください。
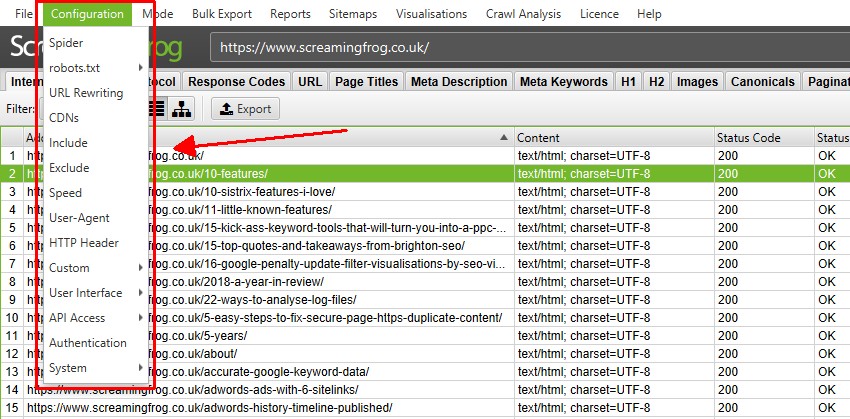
クロールする対象をコントロールする方法としては、特定のサブフォルダをクロールする、除外(URLパターンによるURLのクロールを避ける)、インクルード機能などが一般的です。
また、WebサイトがJavaScriptに依存してコンテンツを入力している場合、「設定 > Spider > レンダリング」でJavaScriptレンダリングモードに切り替えることができます。
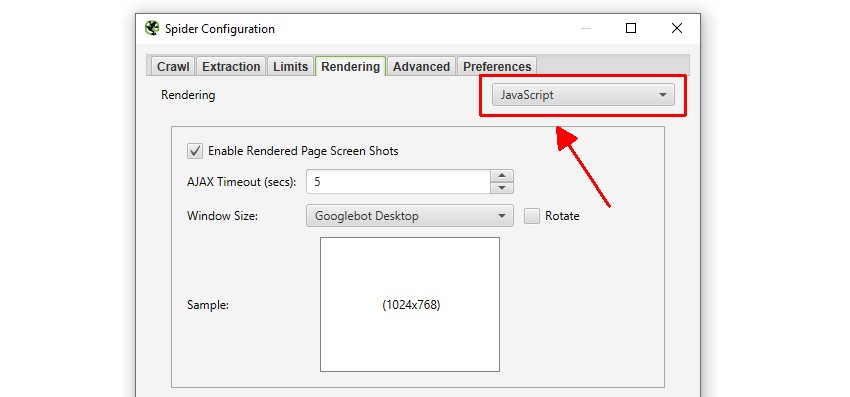
この場合、JavaScriptが実行され、SEO SpiderはレンダリングされたHTML内のコンテンツとリンクをクロールすることになります。
クロールデータの閲覧
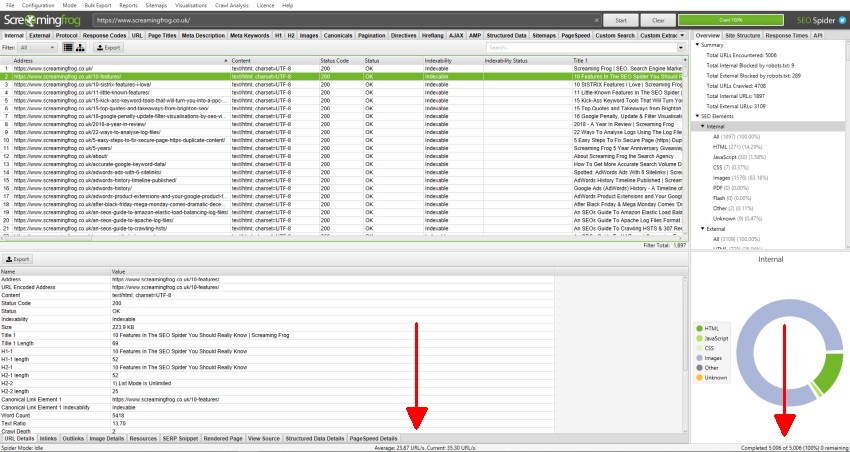
クロールのデータはSEO Spider内にリアルタイムで入力され、タブで表示されます。内部」タブには、クロール中のWebサイトで発見されたすべてのデータが含まれています。上下左右にスクロールすることで、様々なカラムのデータを確認することができます。
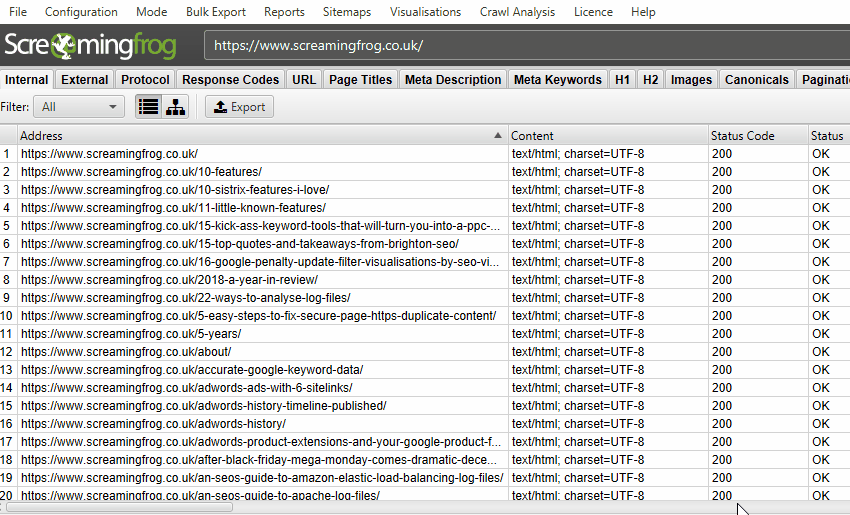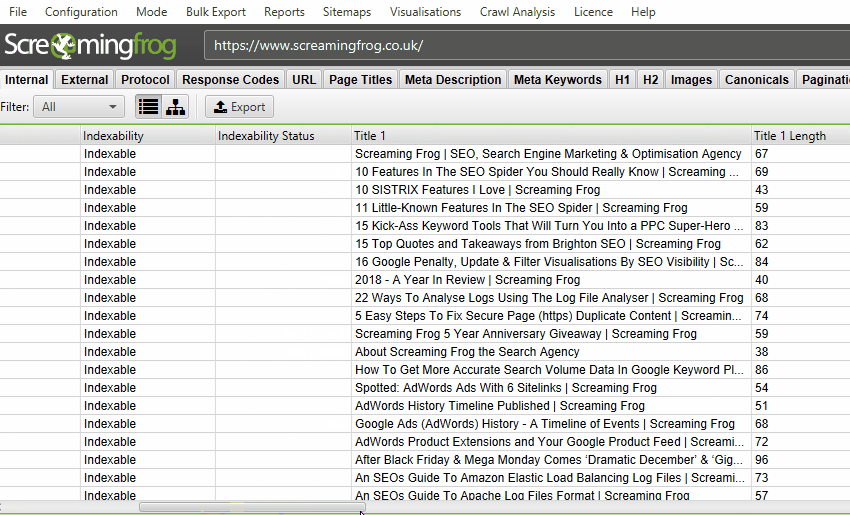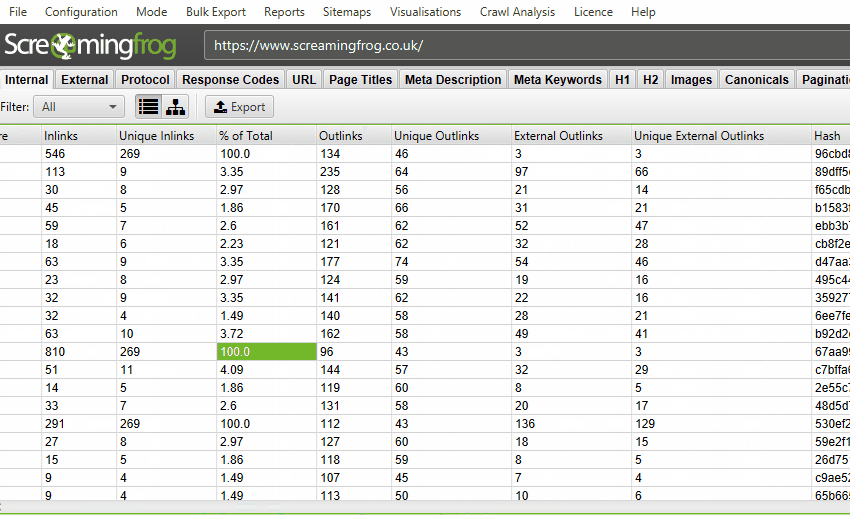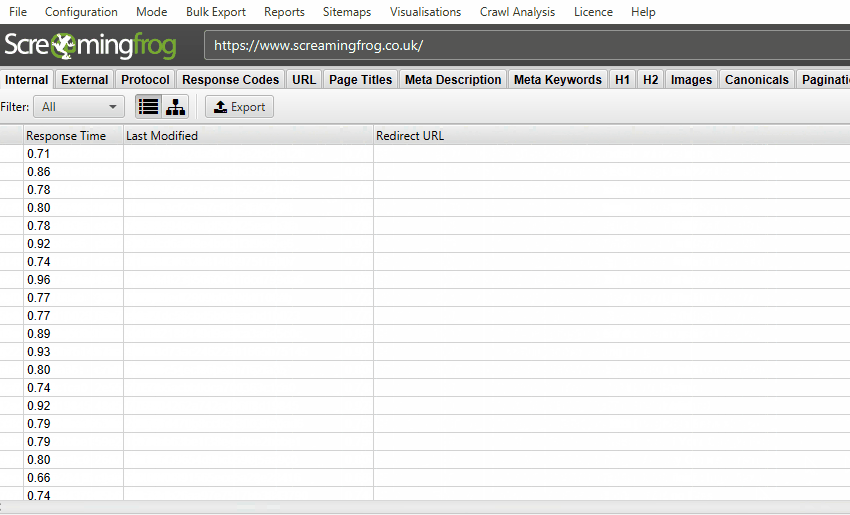
各タブは異なる要素に焦点を当て、データの種類や発見された潜在的な問題によってデータを絞り込むのに役立つフィルターを備えています。
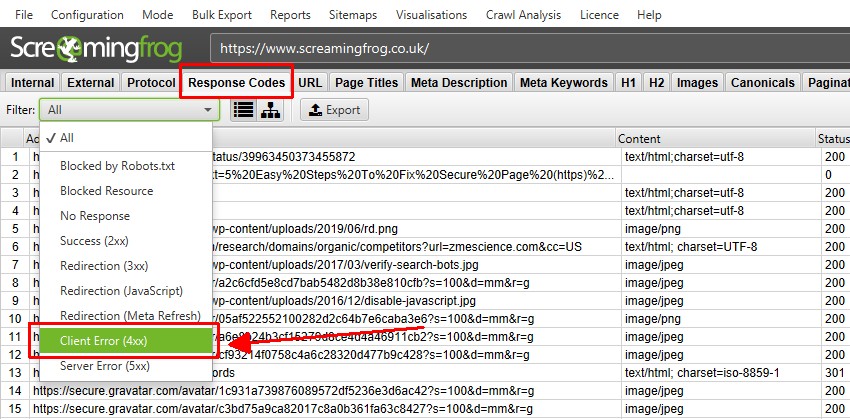
レスポンスコード」タブと「クライアントエラー(4xx)」フィルターでは、例えば404ページが発見された場合、そのページが表示されます。
上部のウィンドウでURLをクリックし、下部にあるタブをクリックすると、下部のウィンドウペインに入力することができます。
これらのタブでは、インリンク(リンク先のページ)、アウトリンク(リンク先のページ)、画像、リソースなど、URLの詳細が表示されます。
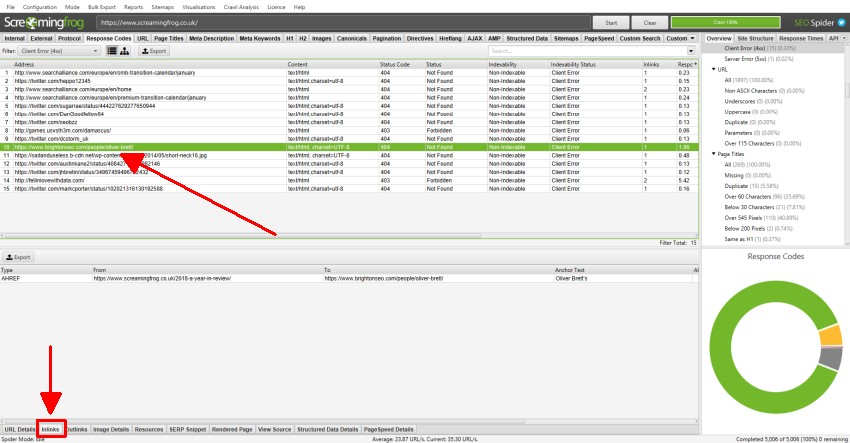
上の例では、クロール中に発見されたリンク切れのインリンクが表示されています。
エラーと問題の発見
右側の「概要」タブには、各タブやフィルターに含まれるクロールデータの概要が表示されます。各タブやフィルターをクリックしなくても、これらのセクションをスクロールして、発見された潜在的なエラーや問題を確認することができます。
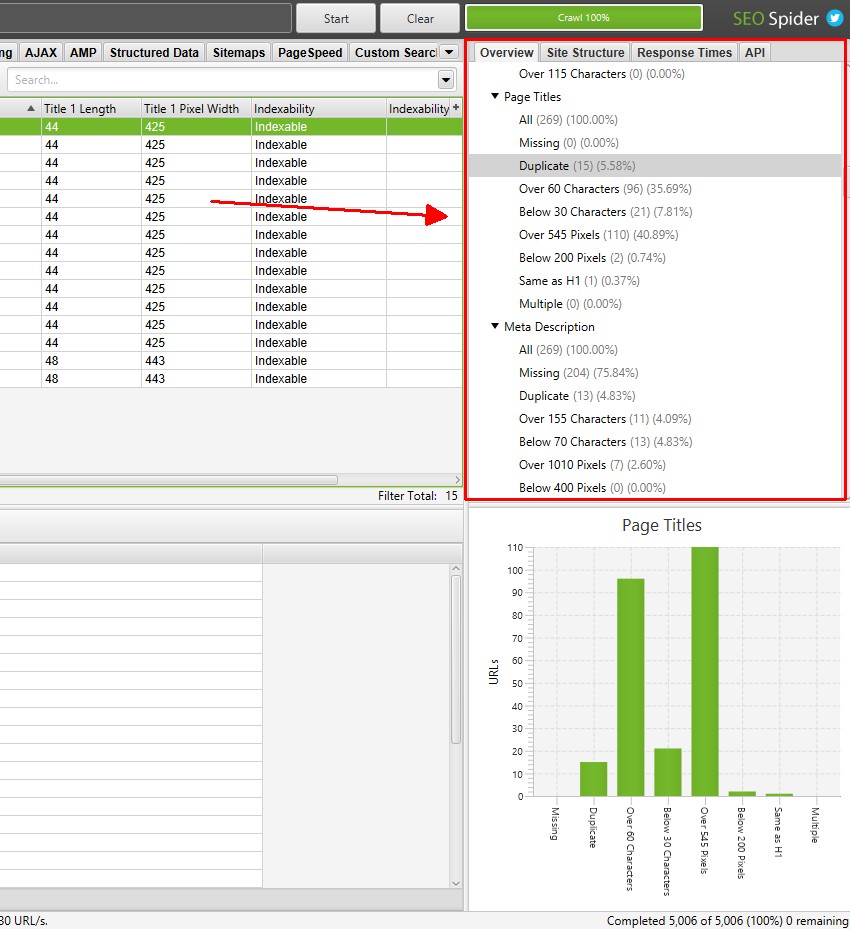
ほとんどのフィルターで、影響を受けたURLの数がクロール中にリアルタイムで更新され、クリックすると該当するタブとフィルターに直接移動することができます。
SEO SpiderはSEOの方法を教えてくれるわけではなく、より多くの情報に基づいた判断を下すためのデータを提供してくれます。しかし、「フィルター」は、あなたのサイトの文脈で、対処すべき、あるいは少なくともさらに検討すべき、特定の問題についてのヒントを提供します。
もし、タブやフィルターの意味がわからない場合は、ユーザーガイドを参照してください。各タブには、各カラムやフィルターについて説明するセクション(ページタイトル、canonicals、directiveなど)があります。
データのエクスポート
クロールからすべてのデータをスプレッドシートにエクスポートすることができます。左上の「エクスポート」ボタンをクリックするだけで、トップウィンドウのタブとフィルターからデータをエクスポートすることができます。
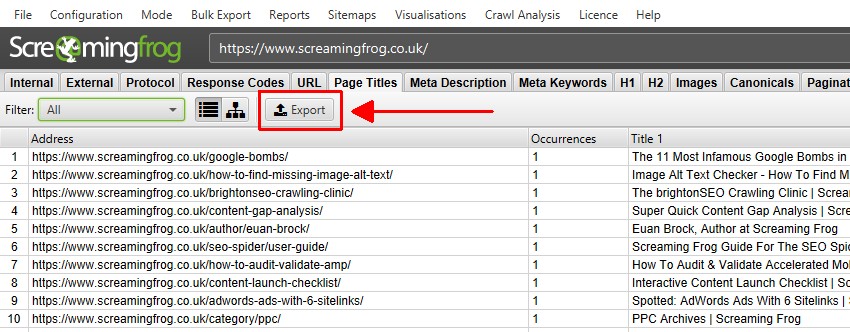
下のウィンドウのデータをエクスポートするには、上のウィンドウでデータをエクスポートしたい URL を右クリックし、いずれかのオプションをクリックします。
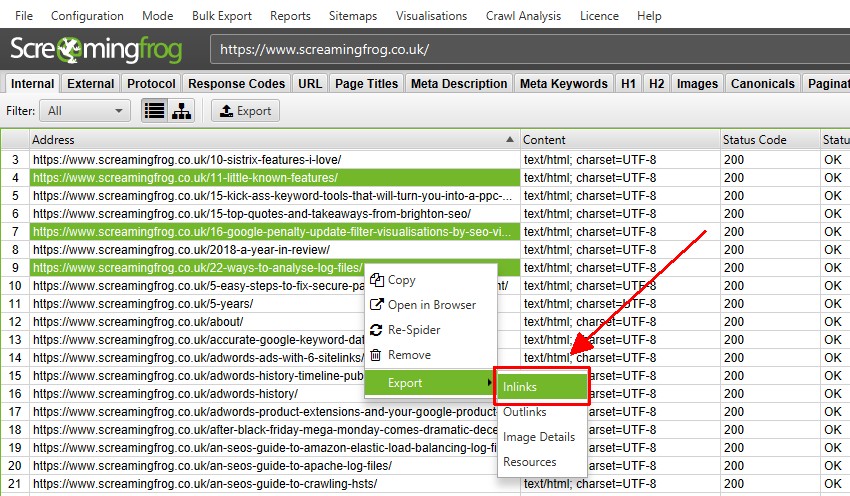
トップレベルメニューの下には、「一括エクスポート」オプションも用意されています。これは、例えば、2XX、3XX、4XX、5XXといった特定のステータスコードを持つURLへの「インリンク」のようなソースリンクをエクスポートすることができるものです。
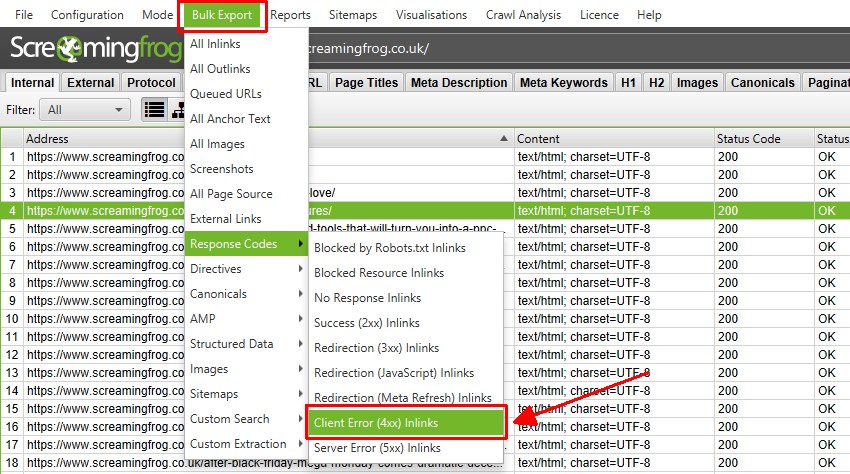
上記で、「Client Error 4XX In Links」を選択すると、すべてのエラーページ(404エラーページにリンクしているページ)へのインリンクがエクスポートされます。
クロールの保存とオープン
クロールを保存したり開いたりできるのは、ライセンスがある場合のみです。デフォルトのメモリ保存モードでは、クロールはいつでも(一時停止中または終了時に)保存でき、「ファイル > 保存」または「ファイル > 開く」を選択して再び開くことができます。
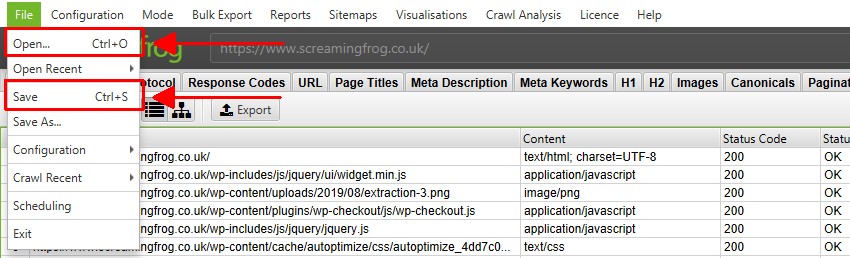
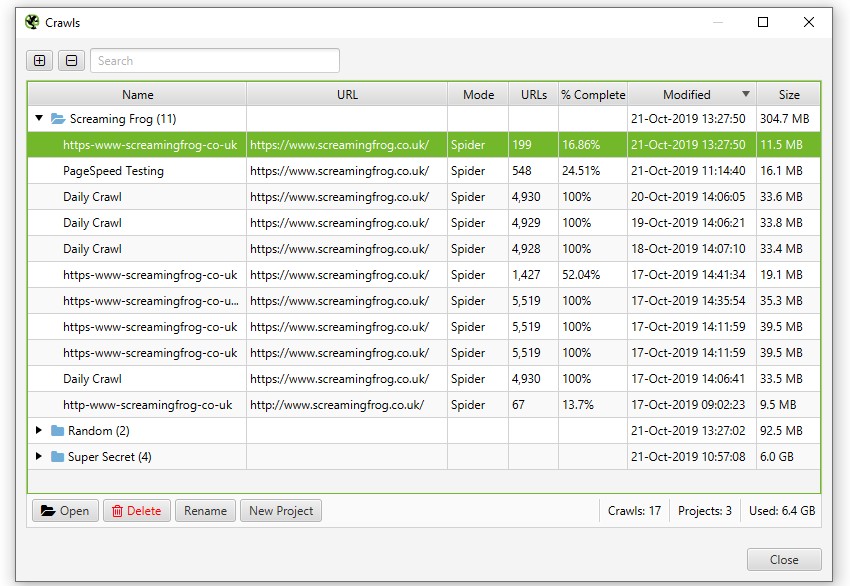
データベース保存モードでは、クロール中に自動的にデータベースに「保存」され、コミットされます。クロールを開くには、メインメニューの’File > Crawls’をクリックします。

Crawls」ウィンドウには、自動的に保存されたクロールの概要が表示され、開く、名前の変更、プロジェクトフォルダへの整理、複製、エクスポート、一括削除を行うことができます。
よく使われる使い方と高度な機能
私たちは、ツールのすべての用途と機能をカバーすることはできませんので、利用可能なオプションを検討し、必要に応じて私たちの徹底したユーザーガイドを参照することをお勧めします。
しかし、SEO Spiderの最も一般的な使い方を、追加資料のリンクと共にリストアップしてみました。
リンク切れの検索 – ウェブサイトを即座にクロールして、リンク切れ(404)やサーバーエラーを検索します。エラーとソースURLを一括エクスポートして、修正したり、開発者に送ったりできます。
リダイレクトの監査 – 一時的および永久的なリダイレクトの検索、リダイレクトチェーンやループの特定、サイト移行時に監査するURLのリストのアップロードが可能です。
ページタイトルとメタディスクリプションの分析 – すべてのページのページタイトルとメタディスクリプションを確認し、最適化されていない要素、見つからない要素、重複している要素、長い要素、短い要素を発見することができます。
ディレクティブと正規表現の確認 – robots.txt、meta robots、X-Robots-Tagディレクティブ(「noindex」「nofollow」など)によってブロックされているURLを表示し、正規表現を確認します。
画像のオルトテキストと属性の検索 – オルトテキストが不足している画像を検索し、クロール内のすべての画像のオルトテキストを表示します。
重複コンテンツのチェック – ページが完全に重複していないか、また「類似」コンテンツが重複していないか、ウェブサイトを分析します。
JavaScript ウェブサイトのクロール – 統合された Chromium WRS を使用してウェブページをレンダリングし、Angular、React、Vue.js などの動的で JavaScript が豊富なウェブサイトとフレームワークをクロールします。
サイトアーキテクチャの可視化 – インタラクティブなクロールとディレクトリフォースディレクション図、およびツリーグラフサイトの可視化により、内部リンクとURL構造を評価します。
XML Sitemaps の生成 – XML Sitemaps と Image XML Sitemaps を迅速に作成し、含める URL、最終更新日、優先度、変更頻度を詳細に設定することができます。
インターナショナルセットアップ(hreflang)の監査 – HTML、HTTPヘッダー、XML Sitemapsにあるhreflangアノテーションの一般的なエラーや問題を大規模に発見します。
PageSpeed & Core Web Vitalsの分析 – PSI APIに接続し、Core Web Vitals(CrUXフィールドデータ)、Lighthouseメトリクス、速度機会、診断を大規模に行うことができます。
また、最も人気のある機能の一部をまとめました。
クロールのスケジュール – SEO Spider内で自動的に実行されるクロールを、1回限り、または選択した間隔でスケジュールします。
クロールとステージングの比較 – SEOの問題と機会の進捗を追跡し、クロールの間に何が変更されたかを確認します。高度なURLマッピングを使用して、ステージングと本番環境を比較します。
GA、GSC、PSIとの統合 – Google Analytics、Search Console、PageSpeed InsightsのAPIに接続し、クロール内のすべてのURLのユーザーとパフォーマンスデータを取得し、より深い洞察を得ることができます。
カスタム検索HTML – ウェブサイトのソースコードから必要なものを検索します。Google Analyticsのコード、特定のテキスト、コードなど、何でも検索できます。
XPathでデータを抽出 – CSS Path、XPath、正規表現を使用して、WebページのHTMLからあらゆるデータを収集します。これには、ソーシャルメタタグ、追加の見出し、価格、SKUなどが含まれる場合があります。
ステージングサイトと開発サイトのクロール – ベーシック、ダイジェスト、ウェブフォーム認証を使用してステージングウェブサイトにログインします。
コマンドライン経由の操作 – コマンドライン経由でプログラム的にクロールを実行し、お客様の内部システムと統合します。
その他のサポート
上記のガイドは、SEOスパイダーの使用を開始するために必要な簡単な手順を説明するのに役立つはずです。
また、Screaming Frog SEO SpiderのFAQ、完全なユーザーガイド、YouTubeチャンネルでツールに関するより詳しい情報をご覧ください。

コメント