重複コンテンツの見つけ方
検索エンジンにとって、あるクエリに対してどのバージョンを上位に表示させるかを決めるのが難しくなるため、ウェブサイト全体で重複するコンテンツは最小限に抑える必要があります。
重複コンテンツのペナルティ」はSEOの神話ですが、非常に類似したコンテンツは、クロールの非効率性を引き起こし、PageRankを低下させ、統合、削除、改善すべきコンテンツの兆候となる可能性があります。
重複コンテンツや類似コンテンツは、ウェブの自然な一部であり、検索エンジンにとっては問題ではないことが多いことを覚えておくとよいでしょう。しかし、規模が大きくなると、より大きな問題になる可能性があります。
重複コンテンツを防ぐことで、検索エンジン任せにするのではなく、何がインデックスされ、ランキングされるかをコントロールすることができます。クロールの予算の無駄を抑え、インデックスとリンクシグナルを統合してランキングに役立てることができます。
このチュートリアルでは、Screaming Frog SEO Spiderを使って、完全な重複コンテンツと、ウェブサイト内のページ間でテキストが一部一致するほぼ同一のコンテンツの両方を見つける方法を説明します。
SEO Spiderを含むどのツールによっても特定された重複コンテンツは、文脈の中で見直す必要があります。ビデオを見るか、以下のガイドをご覧ください。
まずは、SEO Spiderをダウンロードしましょう。500URLまでなら無料でクロールできます。最初の2つのステップは、ライセンスがないと利用できません。無料ユーザーの方は、このガイドの3番まで読み飛ばしてください。
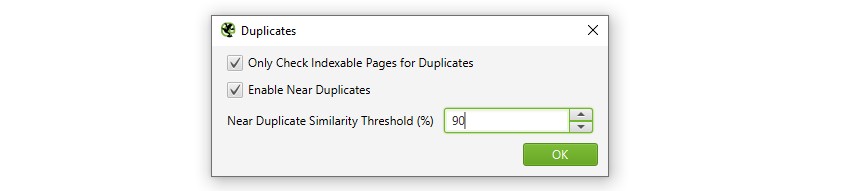
「設定 > コンテンツ > 重複」を通じて、「重複検索」を有効にする
デフォルトでは、SEOスパイダーは自動的に完全な重複ページを特定します。しかし、’Near Duplicates’を識別するためには、各ページのコンテンツを保存できるように設定を有効にする必要があります。
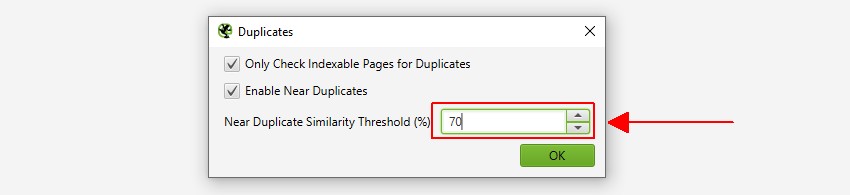
SEO Spiderは類似度90%でニアデュプリケートを特定しますが、より低い類似度の閾値でコンテンツを見つけるように調整することができます。
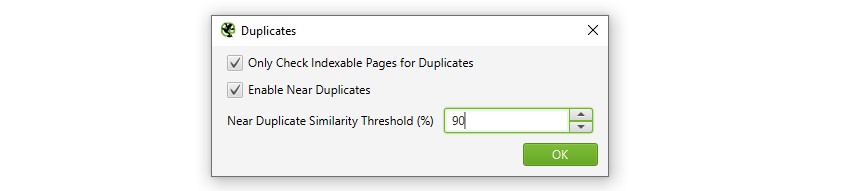
また、SEO Spiderは「インデックス可能な」ページのみ重複をチェックします(完全な重複とほぼ同じ重複の両方について)。
つまり、2つのURLが同じで、一方がもう一方に正規化されている(つまり「インデックスされない」)場合、このオプションが無効になっていなければ、報告されないということです。
クロールの予算の問題を見つけたい場合は、「インデックス可能なページのみ重複をチェックする」オプションのチェックを外すと、クロールの無駄の可能性がある領域を見つけることができます。
「設定」→「コンテンツ」→「エリア」で解析のための「コンテンツエリア」を調整する
重複に近い解析に使用するコンテンツを設定することができます。新規クロールの場合は、デフォルトの設定を使用し、後で分析に使用するコンテンツを確認し、検討できるようになってから、設定を変更することをお勧めします。
SEOスパイダーは自動的にナビとフッターの両要素を除外し、メインボディのコンテンツに焦点を当てます。しかし、すべてのウェブサイトがこれらのHTML5要素を使用して構築されているわけではないので、必要に応じて分析に使用するコンテンツ領域を絞り込むことができます。HTMLタグ、クラス、IDを分析に「含める」または「除外」することができます。
たとえば、Screaming Frogのウェブサイトでは、nav要素の外側にモバイルメニューがあり、デフォルトでコンテンツ分析に含まれます。これはあまり問題ではありませんが、この場合、ページの本文に焦点を合わせるために、そのクラス名「mobile-menu__dropdown」を「除外するクラス」ボックスに入力することが可能です。
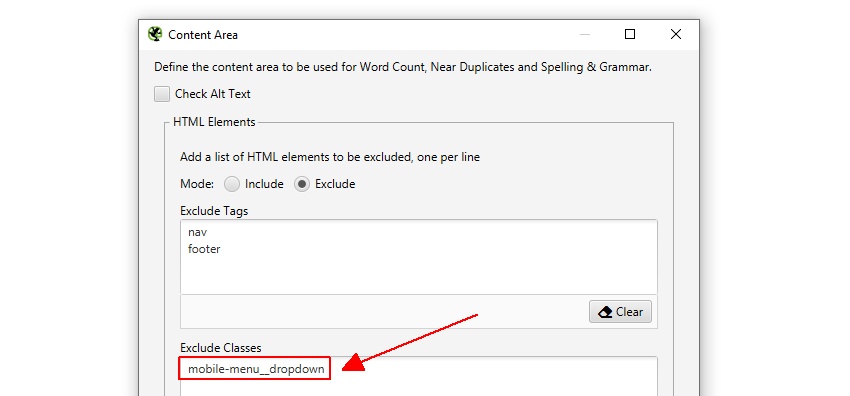
これにより、メニューは重複コンテンツ解析アルゴリズムに含まれなくなります。詳しくは後述します。
ウェブサイトをクロールする
SEOスパイダーを開き、「Enter URL to spider」ボックスにクロールしたいウェブサイトを入力またはコピーして、「Start」をクリックします。
クロールが終了して100%になるまで待ちますが、リアルタイムでいくつかの詳細を表示することも可能です。
「コンテンツ」タブで重複を表示する
コンテンツ」タブには、「完全な重複」と「近い重複」の2つの重複コンテンツに関するフィルターがあります。
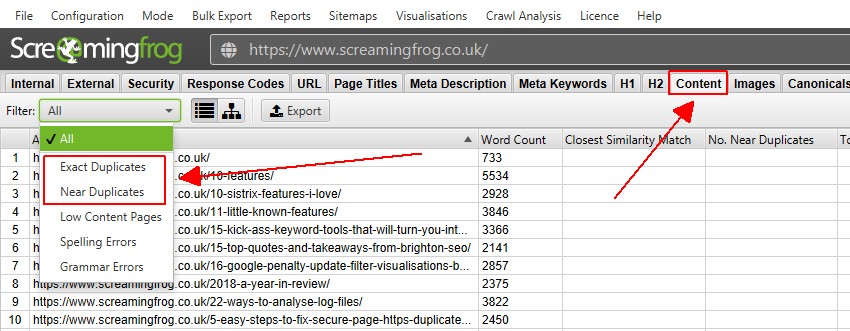
クロール中にリアルタイムで閲覧できるのは「完全な重複」のみです。Near Duplicates」は、クロール終了後に「Crawl Analysis」で計算を行い、データを入力する必要があります。
右側の「概要」ペインでは、クロール後の解析が必要なフィルターに対して「(Crawl Analysis Required)」というメッセージが表示され、データを取り込むことができます。
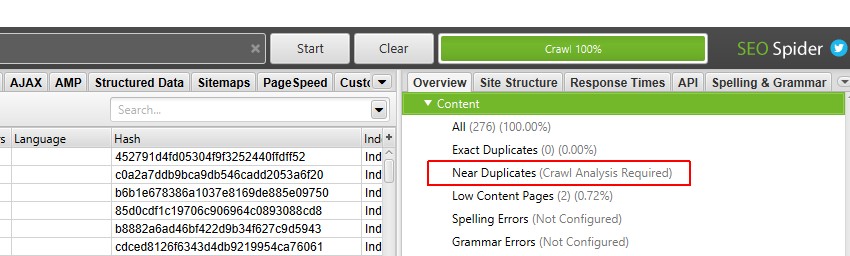
「クロール解析 > 開始」をクリックして、「Near Duplicates」フィルターを設定します
Near Duplicates」フィルター、「Closest Similarity Match」、「No. Near Duplicates」カラムを入力するには、クロール終了時にボタンをクリックするだけです。

ただし、以前に「クロール分析」を設定したことがある場合は、「クロール分析 > 設定」で「Near Duplicates」にチェックが入っていることを再確認してください。
また、クロール後の解析が必要な他の項目のチェックを外すことで、この手順を短時間で行うことができます。
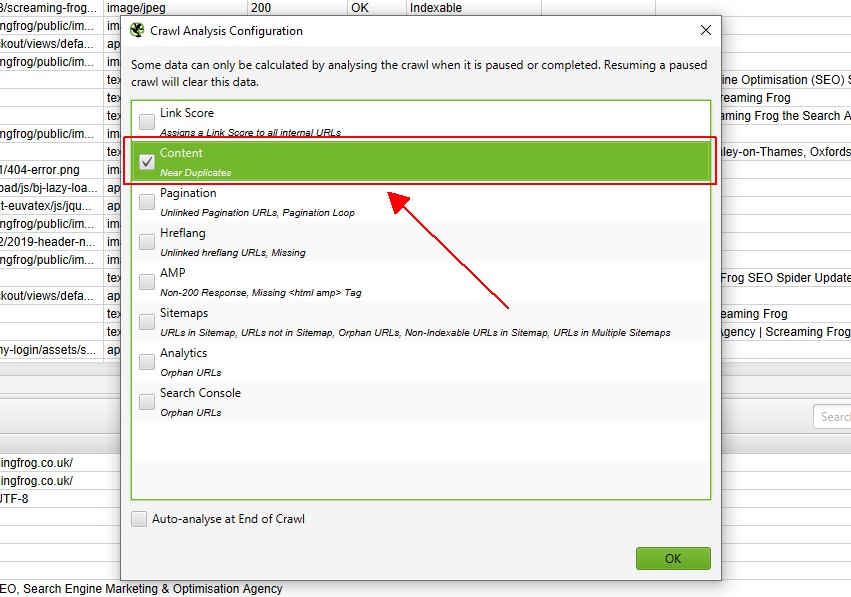
クロール解析が完了すると、「解析」プログレスバーが100%になり、フィルターに「(クロール解析が必要)」というメッセージが表示されなくなります。
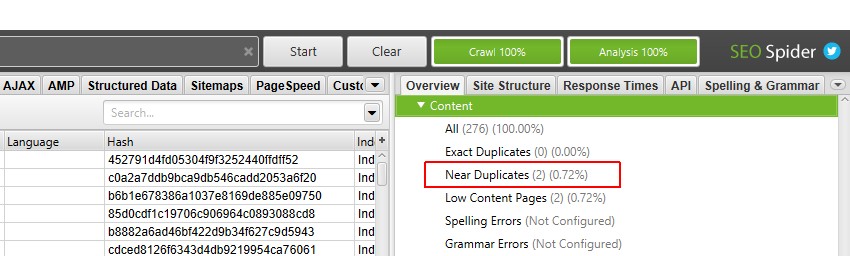
これで、入力されたニアディプリケートフィルタとカラムを確認することができます。
「コンテンツ」タブと「完全」「近接」重複フィルタの表示
ポストクロール解析を行うと、「Near Duplicates」フィルター、「Closest Similarity Match」、「No. Near Duplicates」カラムが入力されるようになります。選択した類似度閾値以上のコンテンツを持つURLのみがデータを含み、その他は空白のままとなります。この場合、Screaming Frogのウェブサイトは2つだけです。
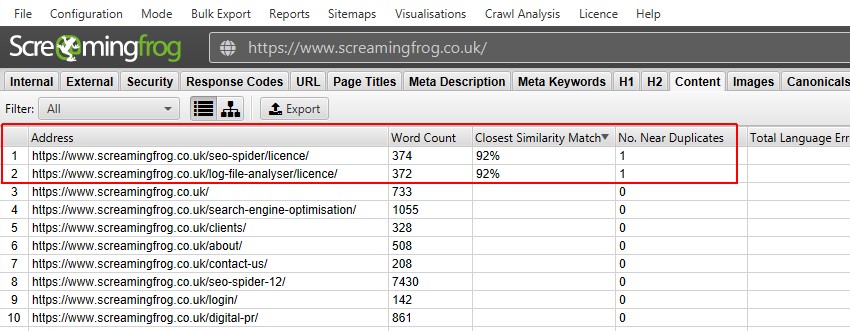
BBCのような大規模なウェブサイトをクロールすると、さらに多くのことがわかります。
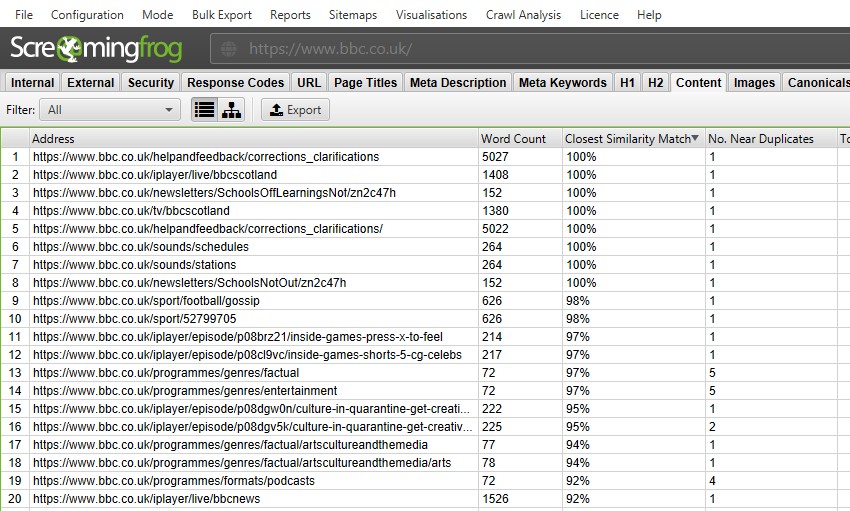
以下の項目でフィルタリングすることができます。
Exact Duplicates
このフィルターは、MD5アルゴリズムを使用して、各ページの「ハッシュ」値を計算し、「ハッシュ」列で見ることができる、互いに同一のページを表示します。このチェックはページの完全なHTMLに対して行われます。ハッシュ値が一致する、まったく同じページがすべて表示されます。完全に重複したページは、PageRankシグナルの分割やランキングの予測不可能性につながる可能性があります。あるURLの正規バージョンは1つだけ存在し、内部的にリンクされている必要があります。他のバージョンはリンクされるべきではなく、正規のバージョンに301リダイレクトされるべきです。
Near Duplicates
このフィルターは、ミンハッシュアルゴリズムを使用して設定された類似性のしきい値に基づき、類似したページを表示します。このしきい値は「設定 > Spider > Content」で調整でき、デフォルトでは90%に設定されています。Closeest Similarity Match’欄には、他のページとの類似度が最も高いページが表示されます。No. Near Duplicates」列には、類似度のしきい値に基づき、そのページと類似しているページの数が表示されます。このアルゴリズムは、完全な重複のようなHTML全体ではなく、ページ上のテキストに対して実行されます。この分析に使用するコンテンツは、「Config > Content > Area」で設定することができます。ページの類似度は100%でも、完全な複製ではなく「ほぼ複製」である場合があります。これは、完全な重複をニアデュプリケートとして除外することで、二重にフラグが立つことを避けるためです。また、類似度のスコアは四捨五入されるため、99.5%以上の場合は100%として表示されます。
特定の属性で検索ボリュームがある製品のバリエーションなど、コンテンツが非常に類似しているページには多くの正当な理由があるため、ニアデュプリケートページは手動で確認する必要があります。
しかし、ほぼ重複と判定されたURLは、ユーザーにとってユニークな価値があるため別のページとして存在すべきか、あるいはコンテンツをより深くユニークにするために削除、統合、改善すべきかを検討するために見直す必要があります。
重複するURLを「重複の詳細」タブで表示する
完全な重複」については、フィルタを使用してトップウィンドウで表示する方が簡単です – グループ化され、同じ「ハッシュ」値を共有しているからです。
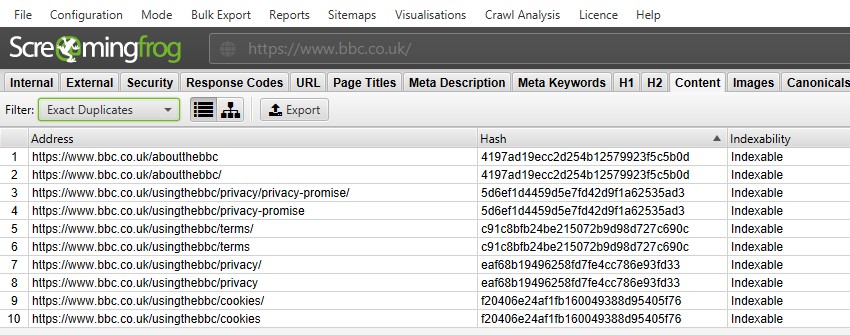
上記のスクリーンショットでは、各URLは、末尾のスラッシュと末尾以外のスラッシュのバージョンにより、対応する完全な重複を持ちます。
ほぼ同じURLの場合、下部の「重複の詳細」タブをクリックすると、検出された各URLの「ほぼ同じアドレス」と類似度が下部のウィンドウペインに表示されます。
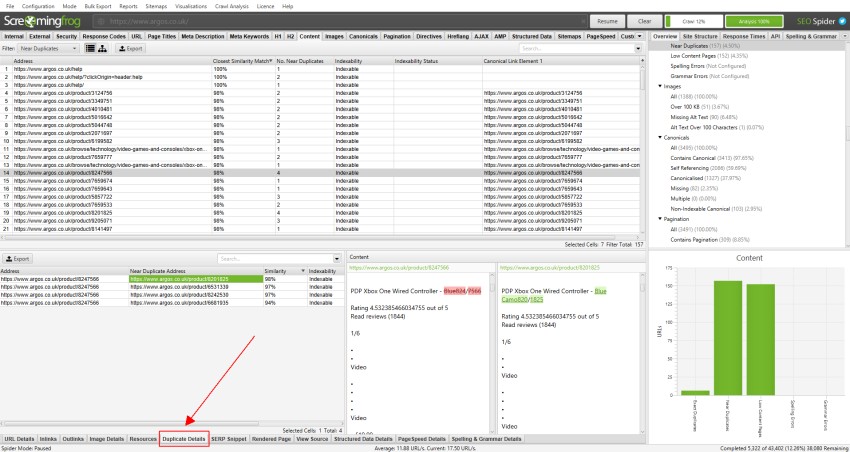
例えば、上部のウィンドウに表示されているURLの中に、4つのニアデュプリケート(重複)が発見された場合、それらをすべて表示することができます。
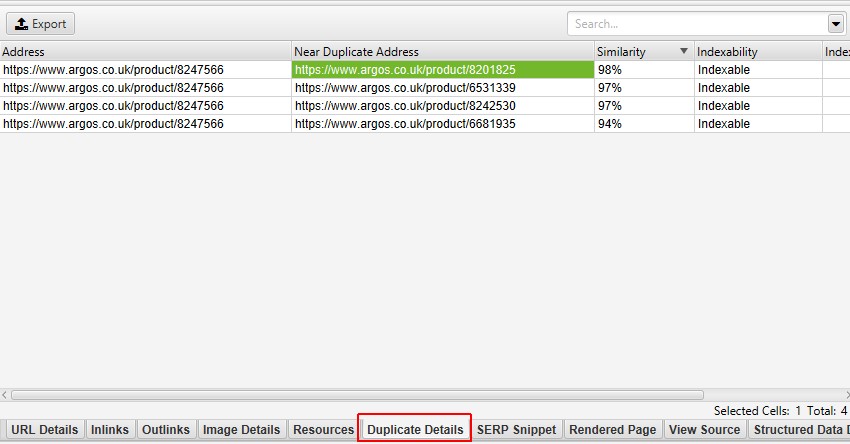
重複の詳細」タブの右側には、ページから発見された重複に近いコンテンツが表示され、それぞれの「重複に近いアドレス」をクリックすると、ページ間の相違点が強調表示されます。
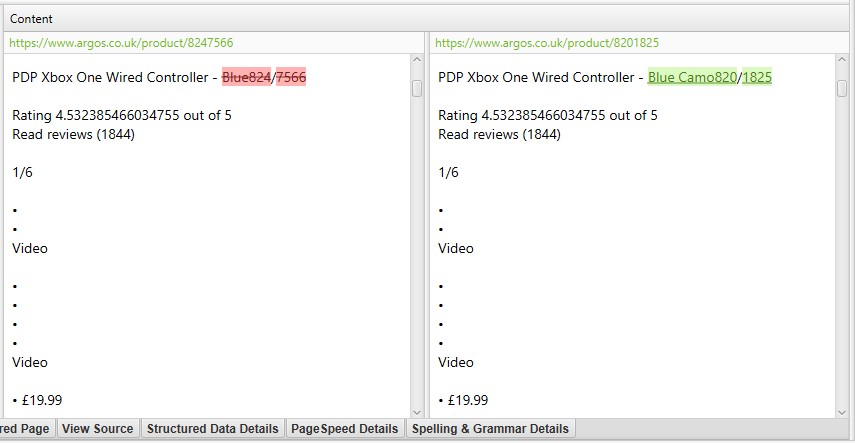
重複コンテンツの詳細]タブに重複コンテンツ解析の対象としたくないコンテンツがある場合、HTML要素、クラス、ID(ポイント2で強調したとおり)を除外または含め、クロール解析を再実行します。
重複コンテンツの一括エクスポート
完全な重複とほぼ同等の重複を、「一括エクスポート > コンテンツ > 完全な重複」「ほぼ同等の重複」のエクスポートで一括してエクスポートすることができます。

最後のヒント 類似度のしきい値とコンテンツ領域を絞り込み、クロール解析を再実行する
クロール後、ニアディプリケート分析に使用する類似度閾値とコンテンツ領域の両方を調整することができます。
また、クロール解析を再度実行することで、Webサイトを再クロールすることなく、より類似したコンテンツやより劣るコンテンツを見つけることができます。
前述したように、Screaming Frogのウェブサイトには、nav要素の外側にモバイルメニューがあり、デフォルトでコンテンツ分析の対象に含まれています。モバイルメニューは、「重複の詳細」タブのコンテンツプレビューで確認することができます。
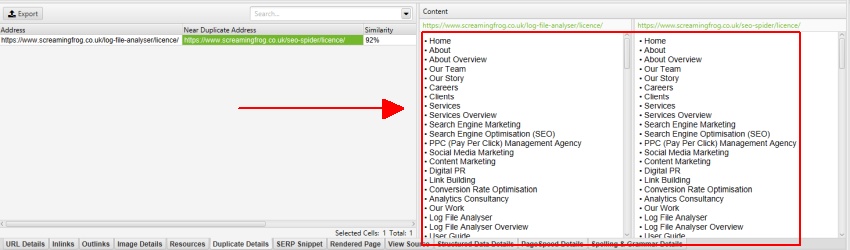
設定>コンテンツ>エリア」の「除外クラス」で「mobile-menu__dropdown」を除外することで、コンテンツプレビューとニアダプリケート分析からモバイルメニューが削除されます。
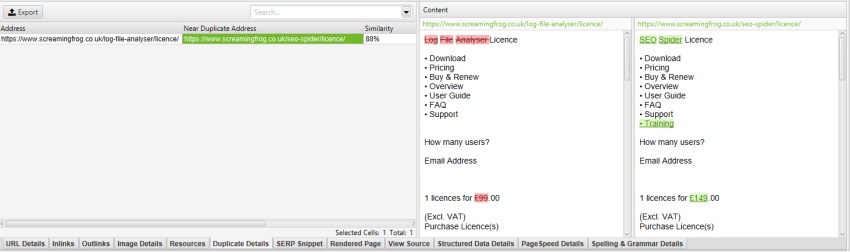
これは、再クロールの必要なく、メインコンテンツ領域とのニアディプリケートコンテンツの識別を微調整する際に非常に有効です。
まとめ
上記のガイドは、SEO Spiderをあなたのウェブサイトの重複コンテンツ・チェッカーとして使用する方法を説明するものです。最も正確な結果を得るためには、分析するコンテンツエリアを絞り込み、異なるページグループに対して閾値を調整します。

コメント